Spectral Compressive Imaging via Unmixing-driven Subspace Diffusion Refinement
*Equal contribution, †Corresponding author
Abstract
Spectral Compressive Imaging (SCI) reconstruction is inherently ill-posed, offering multiple plausible solutions from a single observation. Traditional deterministic methods typically struggle to effectively recover high-frequency details. Although diffusion models offer promising solutions to this challenge, their application is constrained by the limited training data and high computational demands associated with multispectral images (MSIs), complicating direct training. To address these issues, we propose a novel Predict-and-unmixing-driven-Subspace-Refine framework (PSR-SCI). This framework begins with a cost-effective predictor that produces an initial, rough estimate of the MSI. Subsequently, we introduce a unmixing-driven reversible spectral embedding module that decomposes the MSI into subspace images and spectral coefficients. This decomposition facilitates the adaptation of pre-trained RGB diffusion models and focuses refinement processes on high-frequency details, thereby enabling efficient diffusion generation with minimal MSI data. Additionally, we design a high-dimensional guidance mechanism with imaging consistency to enhance the model's efficacy. The refined subspace image is then reconstructed back into an MSI using the reversible embedding, yielding the final MSI with full spectral resolution. Experimental results on the standard KAIST and zero-shot datasets NTIRE, ICVL, and Harvard show that PSR-SCI enhances visual quality and delivers PSNR and SSIM metrics comparable to existing diffusion, transformer, and deep unfolding techniques. This framework provides a robust alternative to traditional deterministic SCI reconstruction methods. [Code and models]
Key Contributions
- (i) A spectral unmixing-driven predict-and-subspace refine strategy (PSR-SCI) for SCI reconstruction that yields improved perceptual quality over deterministic methods and more efficient enhancement than typical diffusion models.
- (ii) A reversible decomposition module that utilizes hierarchical decomposition to efficiently implement spectral subspace learning while maintaining high reversibility.
- (iii) Focus on diffusion generation exclusively for high-frequency components, accelerating fine-tuning and significantly reducing required training data.
- (iv) High-dimensional guidance with SCI imaging consistency to enhance model efficacy.
Related Works
The existing framework for SCI reconstruction predominantly consists of model-based, Plug-and-Play, End-to-end (E2E), and Deep unfolding methods.
- Model-based methods depend on hand-crafted image priors but require manual parameter tuning and have limited representation capacity.
- Plug-and-play (PnP) algorithms incorporate pre-trained denoising networks into traditional model-based methods but are limited by fixed pre-trained networks.
- End-to-end (E2E) algorithms leverage CNNs to establish a mapping function but often neglect fundamental principles of SCI systems.
- Deep unfolding methods utilize multi-stage networks with interpretability through explicit characterization of image priors.
- Diffusion models - Recent works like DiffSCI utilize pre-trained denoising diffusion models for RGB images as the denoiser within the PnP framework.
Method: PSR-SCI Framework
1. Snapshot Compressive Imaging and Problem Setup
In a CASSI system, an MSI \( \mathcal{X} \in \mathbb{R}^{H \times W \times B} \) is projected into a 2D measurement \( \mathcal{Y} \in \mathbb{R}^{H \times (W + d(B-1))} \) via coded spectral modulation. The imaging model can be formulated as: \[ \mathbf{y} = \mathbf{\Phi} \mathbf{x} + \mathbf{n}, \] where \( \mathbf{\Phi} \) encodes spectral-shifted masks, and \( \mathbf{x} \) is the vectorized MSI. Reconstructing \( \mathbf{x} \) from \( \mathbf{y} \) is ill-posed and benefits from strong generative priors.
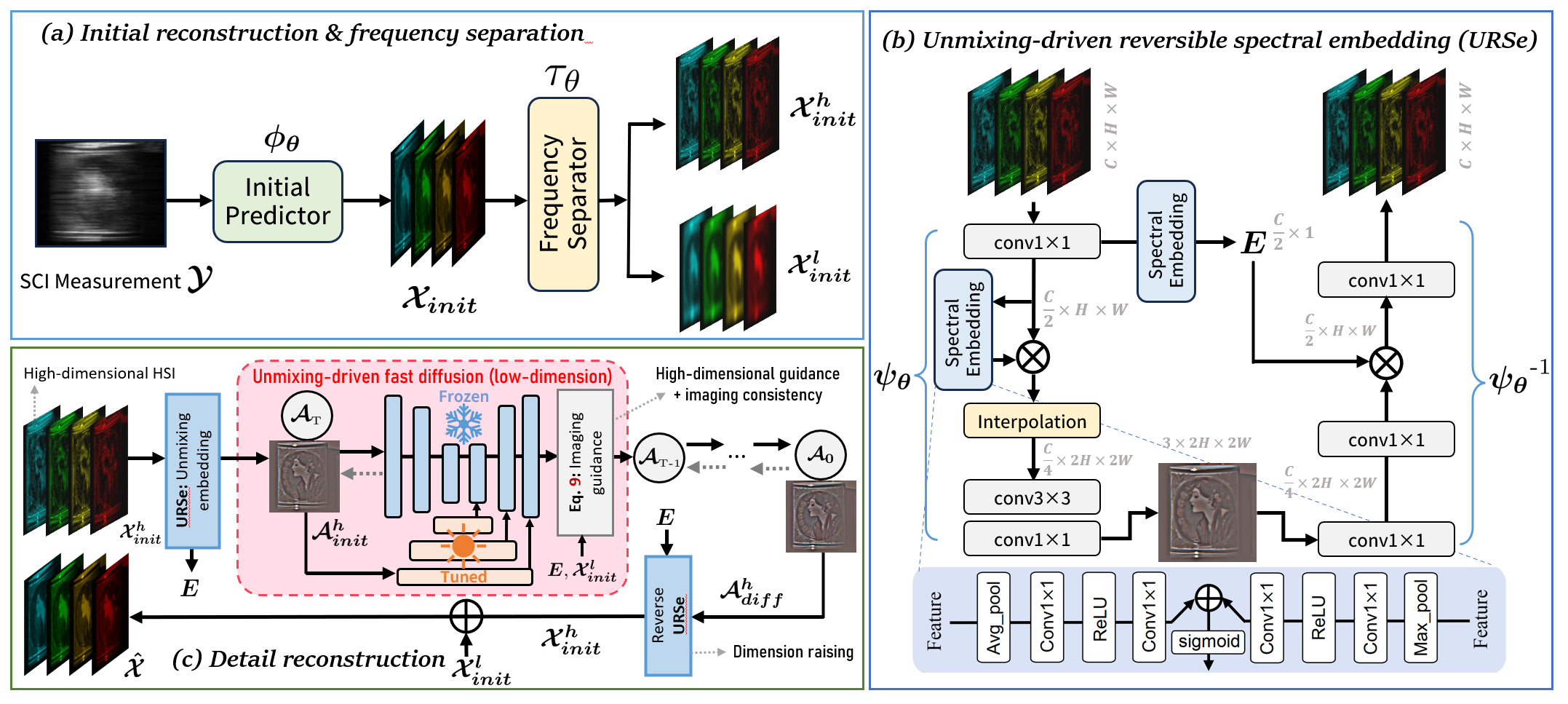
2. Predict-and-Subspace-Refine Framework
We first estimate a coarse MSI \( \mathcal{X}_{\textit{init}} = \phi(\mathcal{Y}) \) via a trained predictor. Then, a learnable frequency separator \( \tau \) splits it into high- and low-frequency parts: \( (\mathcal{X}^h, \mathcal{X}^l) = \tau(\mathcal{X}_{\textit{init}}) \). The high-frequency part is embedded into subspace form: \[ (\mathcal{A}^h, E) = \psi(\mathcal{X}^h), \] where \( \mathcal{A}^h \) is a low-rank abundance map and \( E \) encodes spectral coefficients. This enables refinement via diffusion on \( \mathcal{A}^h \), with final MSI recovered as: \[ \hat{\mathcal{X}} = \psi^{-1}(\mathcal{A}^h_{\textit{diff}}, E) + \mathcal{X}^l. \]
3. Reversible Spectral Embedding (URSe)
The URSe module implements invertible unmixing via hierarchical convolutions and spectral attention, ensuring minimal information loss. Unlike direct compression, URSe guarantees structural recovery of the MSI from latent subspace.
4. Diffusion Refinement with High-Dimensional Guidance
We adapt pretrained Stable Diffusion (2.1-base) for subspace refinement. A parallel encoder allows tuning on small MSI datasets. To enforce measurement consistency, we introduce a high-dimensional guidance loss: \[ \mathcal{L} = \|\mathcal{Y} - \Phi(\psi^{-1}(\mathcal{D}(\hat{\mathcal{z}}_0), E) + \mathcal{X}^l) \|^2. \] This forms a guided reverse SDE that jointly optimizes perceptual quality and physical realism.
Experimental Results
Quantitative Evaluation
| Algorithms | Category | Reference | Average PSNR/SSIM |
|---|---|---|---|
| DeSCI | Model | TPAMI 2019 | 25.27 / 0.748 |
| \(\lambda\)-Net | CNN | ICCV 2019 | 28.53 / 0.841 |
| TSA-Net | CNN | ECCV 2020 | 31.35 / 0.895 |
| HDNet | Transformer | CVPR 2022 | 34.66 / 0.946 |
| MST-L | Transformer | CVPR 2022 | 34.81 / 0.949 |
| MST++ | Transformer | CVPR 2022 | 35.72 / 0.955 |
| DAUHST | Deep Unfolding | NeurIPS 2022 | 37.21 / 0.959 |
| DAUHST-3stg | Deep Unfolding | NeurIPS 2022 | 37.21 / 0.959 |
| DAUHST-SP2 | Subspace prior | Information Fusion 2024 | 37.61 / 0.966 |
| DiffSCI | Diffusion | CVPR 2024 | 35.28 / 0.916 |
| PSR-SCI-T | Diffusion | ICLR 2025 (Ours) | 36.68 / 0.961 |
| PSR-SCI-D | Diffusion | ICLR 2025 (Ours) | 38.14 / 0.967 |
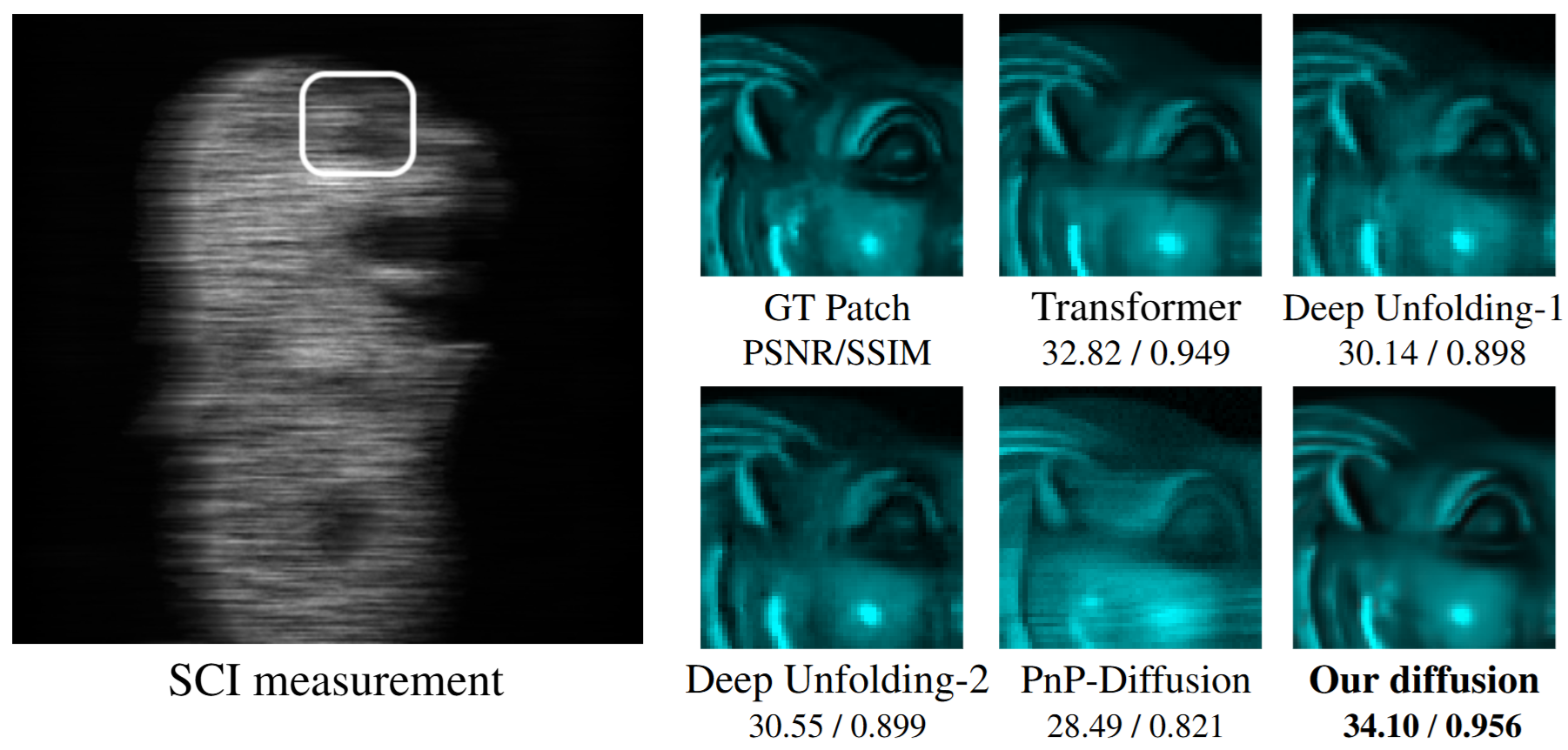
Our PSR-SCI-D model achieves state-of-the-art performance across all metrics on the KAIST dataset, with an average PSNR of 38.14dB and SSIM of 0.967 - an improvement of nearly 1.4dB compared to leading diffusion-based methods. The PSR-SCI-T variant also demonstrates competitive performance, highlighting the effectiveness of our approach.
Qualitative Results


Zero-Shot Generalization

Computational Efficiency
Our PSR-SCI model significantly reduces the computational burden, requiring only 8.9 seconds for 50 sampling steps compared to 85 seconds for state-of-the-art diffusion-based methods, while achieving superior performance.
Conclusion
We introduced a new framework for spectral compressive imaging reconstruction that focuses on reconstructing high-frequency details by fine-tuning a diffusion model pre-trained on large-scale RGB images. Our empirical results demonstrate significant improvements in detail quality and superior metrics compared to current state-of-the-art methods. We believe that our work introduces a novel direction in spectral compressive imaging reconstruction and establishes a robust benchmark for future research.
Citation
@inproceedings{zeng2025spectral,
title={Spectral Compressive Imaging via Unmixing-driven Subspace Diffusion Refinement},
author={Zeng, Haijin and Sun, Benteng and Chen, Yongyong and Su, Jingyong and Xu, Yong},
booktitle={The Thirteenth International Conference on Learning Representations}
year={2025}
}